强化学习(Reinforcement Learning)学习笔记(一)
0. 前言
因为入职之前需要完成公司安排的红心大战的task,所以在改论文之余稍微学习了一下强化学习。选择了Alpha Go第一作者David Sliver在伦敦大学的强化学习课程。
0.1 资料
- 视频资源Youtube 或者b站搜索强化学习
- 推荐书籍:
0.2 课程目录
- Lecture 1: Introduction to Reinforcement Learning
- Lecture 2: Markov Decision Processes
- Lecture 3: Planning by Dynamic Programming
- Lecture 4: Model-Free Prediction
- Lecture 5: Model-Free Control
- Lecture 6: Value Function Approximation
- Lecture 7: Policy Gradient Methods
- Lecture 8: ntegrating Learning and Planning
- Lecture 9: Exploration and Exploitation
- Lecture 10: Case Study: RL in Classic Games
1. 强化学习简介
强化学习(Reinforcement Learning ,RL)的知识涉及到很多领域的知识,如CS、数学、经济学、神经学等。如下图所示。
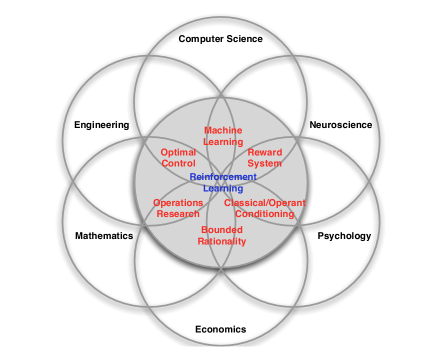
1.1 RL的特点
相较于其他机器学习算法,D.Sliver认为Rl有以下特点:
- 强化学习是一种无监督学习,只有对机器的奖励(Reward)信号
- 反馈是延迟的,需要经历很多步之后才会知道选择是否正确
- 时间十分重要,处理的是一个动态的系统,处理的是独立同分布的信息。agent和环境相互交互
- Agent的每一步操作会影响到其得到的数据序列,是一种主动式的学习
1.2 Example
强化学习在工程上可以用在很多场景下,D.Sliver提到的为几种样例:
- 无人直升机飞行特效表演。直升机在不断尝试中学会什么是正确的飞行姿态。
- 在棋类游戏中不断学习,战胜人类玩家。如AlphaGo
- 管理资本投资
- 控制电力系统
- 机器人行走
- 电子游戏
2. RL的一些要点
2.1 Rewards
Reward($R_t$)在强化学习中是一个反馈标量信号,用来衡量agent在第t步行为的好坏。整个算法的目的就是为了在结束时使累计奖励最大化。强化学习算法建立在假设奖励之上。Agent通过Rewards知道自身决策是否正确。
在强化学习中,所需要做的事情就是选择不同的行动(action),使未来总的奖励最大化。因为每一步行动带来的后果并不一定立即生效,有可能会带来长远的影响,所以奖励也是延迟的。为了使强化学习的效果更好,在当前奖励和长期奖励中,agent应该选择牺牲当前奖励以获得更多的长期奖励。
如在一次经济决策中,需要几个月才能看到收益。在控制直升机时,一次加油可能会避免几个小时后的一次事故。
2.2 Agent与Environment(环境)
以人的大脑做出决策为例来简单介绍Agent与Environment之间的关系。如下图所示。
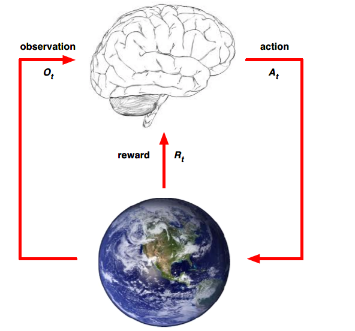
在第t步的决策当中,大脑作为一个agent,通过观察从环境中获得信息$Ot$,同时获得奖励$R_t$,基于此,做出行动$A_t$。同时,环境得到agent做出的$A_t$,同时向agent发出$O{t+1}$与$R_{t+1}$.以此反复。
2.3 History 与 State
History是一系列观测结果,行动以及奖励的序列,可表示为:
也就是说history是所有与 t有关的可观测到的变量,是agent可以感测到的所有变量。
从定义中可以看出,整个系统下一步会发生什么完全取决于history。
State是用来决定下一步会发生什么的信息,是关于history的函数
2.3.1 Environment State(环境状态,$S_t^e$)
Environment State指的是环境用来选择下一步中的可观测量和奖励时所需要的信息,通常对agent来说是不可见的,即使可见,也有可能包含很多与决策无关的信息。
2.3.2 Agent State($S_t^a$)
$S_t^a$是agent的内部特征,包括agent用来做出下一步行动的信息,是强化学习算法使用的信息,是关于history的函数
2.3.3 Information State
Information State(也可以叫做Markov State)包括可以从history中得到的所有有用信息。
定义:
如果一个状态是Markov,那么当且仅当
也就是说t+1状态发生的概率仅与t状态有关,与之前所有状态无关。
在强化学习中,可以理解为$H{1:t}\rightarrow S_t\rightarrow H{t+1:\infty}$,,一旦state确定了,history就不再有用。
$S_t^e$符合Markov,history$H_t$也符合Markov
2.4 Fully Observable Environment
Fully Observable指agent可以之间观测到环境状态$S_t^e$,即
Agent State = Environment State = Information State
这是一个Markov 决策过程(Markov decision process,MDP)
2.4 Partially Observable Environment
部分可观测指agent不能直接观测到环境,在工程中,比如机器人不能通过摄像头知道自己的绝对位置,在扑克牌中无法知道其他牌手的牌等。
这是一个部分可观测马尔科夫决策过程(POMDP)
agent必须自己来创建自己的状态表达$S_t^a$
- 通过全部的历史:$S_t^a=H_t$
- 通过贝叶斯方法,使用概率:$S_t^a=(P[S_t^e=s^1],\dots ,P[S_t^e=s^n])$,通过自己估计环境状态发生的概率来决定自己
- 通过循环神经网络(RNN)
3. Agent的内部信息
强化学习agent通常包括Policy(策略)、Value function(价值函数)以及Model(模型)
- Policy是指agent的行为函数
- Value function是用来平均某一个状态或行为的
- Model 是agent对环境的表述,即agent眼里的世界
3.1 Policy
policy是agent自身的行为,即agent根据当前状态做出的行动。是state到action的映射。
如果policy是可以确定的,那么就会有一个函$\pi$,其自变量为状态s,因变量是行为a,可以表达为:
与之相对的,还有一种情况就是policy不能准确确定,也就是说其选择是由概率的,可是表示为:
3.2 Value Function
价值函数Value Function是对未来reward的预测,用来评价状态的好坏。
上式指的式价值函数计算的是未来奖励的期望,但agent更关心t+1时刻的奖励,对越远的奖励越不关心,系数为0~1.
3.3 Model
agnet用Model来预测接下来会发生什么,用P来预测接下来的状态,用R来预测接下来的奖励
3.4 Example
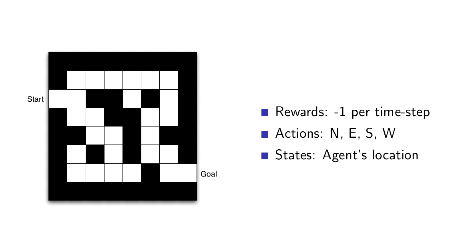
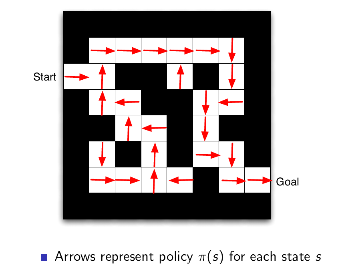
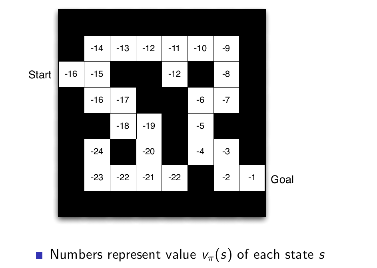
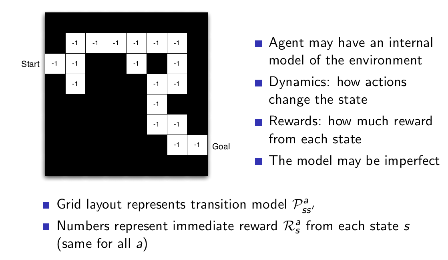
3.5 强化学习agent分类
1) 基于价值(Value Based) 基于策略(Policy Based)Actor-Crotic
2) 基于模型 Model Free
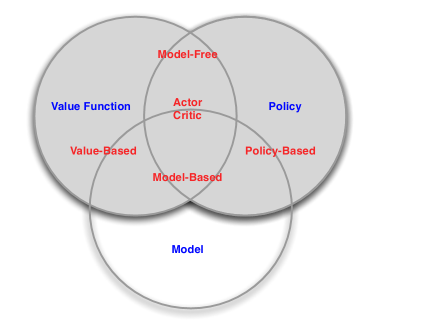
4. 其他问题
4.1 强化学习与规划问题
- 强化学习
- 环境模型未知
- agent和环境相互影响
- agent完善策略
- 规划问题
- 环境的模型已知
- agent和环境没有任何外部交互
- agent完善策略